a) A graphical models for event recognition in photo albums

|
We propose an enhanced latent topic model based on latent Dirichlet allocation and convolutional neural nets
for event classification and annotation in images. Our model builds on the semantic structure relating events,
objects and scenes in images. Based on initial labels extracted from convolution neural networks (CNNs), and
possibly user-defined tags, we estimate the event category and final annotation of an image through a refinement
process based on the expectationmaximization (EM) algorithm. The EM steps allow to progressively ascertain the
class category and refine the final annotation of the image. Our model can be thought of as a two-level annotation
system, where the first level derives the image event from CNN labels and image tags and the second level derives the
final annotation consisting of event-related objects/scenes. Experimental results show that the proposed model yields
better classification and annotation performance in the two standard datasets: UIUC-Sports and WIDER.
Paper :
- (with L. Laib and S. Ait Aoudia). A probabilistic topic model for event-based image classification and multi-label annotation. SPIC, 76: 283-294, 2019.
|
b) Topic model for event-based image classification and annotation

|
We propose a probabilistic graphical model (PGM) for event prediction based on high-level visual features consisting of objects and scenes,
which are extracted directly from images. For better discrimination between different event categories, we develop a scheme to integrate feature relevance in our model
which yields a more powerful inference when album images exhibit a large number of objects and scenes. It allows also to mitigate the
influence of non-informative images usually contained in the albums. The performance of the proposed method is validated using extensive
experiments on the recently-proposed PEC dataset containing over 61 000 images. Our method obtained the highest accuracy which outperforms previous work.
Papers :
- (with S. Bacha and N. Benblidia). Event recognition in photo albums using probabilistic graphical models and feature relevance. JVCIR, 40: 546-558, 2016.
- (with S. Bacha). Feature Relevance in Bayesian Network Classifiers and Application to Image Event Recognition. FLAIRS Conference, 760-763, 2017.
|
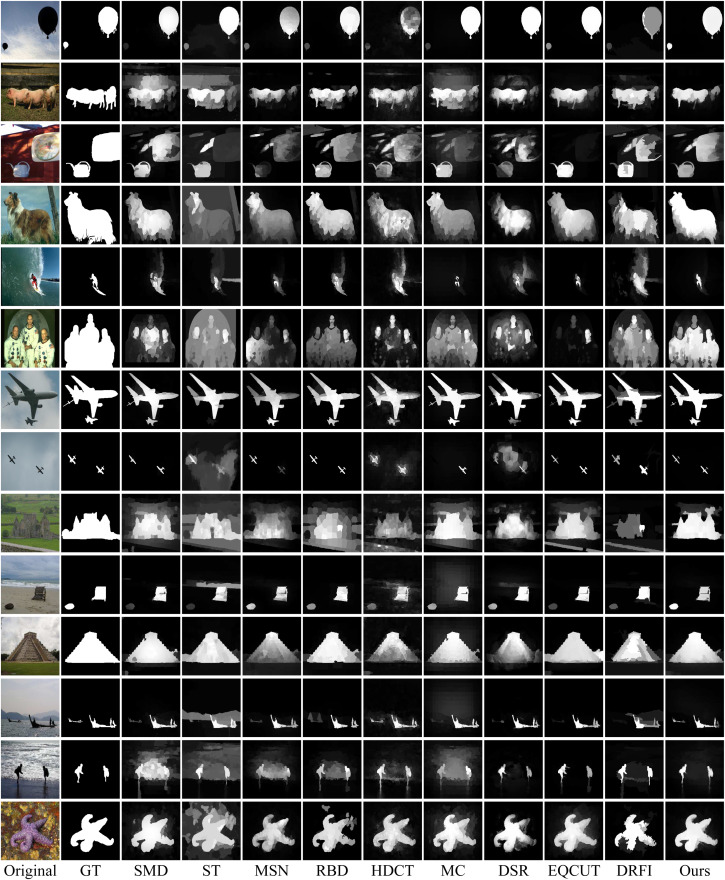
a) A supervised approach for defect detection in fabric images

|
A learning-based approach for automatic detection of fabric defects is proposed. Our approach is based on a
statistical representation of fabric patterns using the redundant
contourlet transform (RCT). The distribution of the RCT coefficients are modeled using a finite mixture of generalized Gaussians
(MoGG), which constitute statistical signatures distinguishing
between defective and defect-free fabrics. In addition to being
compact and fast to compute, these signatures enable accurate
localization of defects. Our defect detection system is based on
three main steps. In the first step, a preprocessing is applied
for detecting basic pattern size for image decomposition and
signature calculation. In the second step, labeled fabric samples
are used to train a Bayes classifier (BC) to discriminate between
defect-free and defective fabrics. Finally, defects are detected
during image inspection by testing local patches using the learned
BC. Our approach can deal with multiple types of textile fabrics,
from simple to more complex ones. Experiments on the TILDA
database have demonstrated that our method yields better results
compared with recent state-of-the-art methods.
Paper :
- (with L. Laib and S. Ait Aoudia). A probabilistic topic model for event-based image classification and multi-label annotation. SPIC, 76: 283-294, 2019.
|
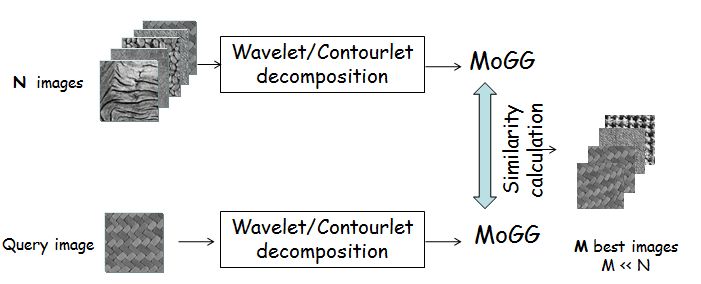
b) Texture classfication and retieval using wavelets/contourlets and the MoGG modeling
(DATA,
CODE)
|
Texture analysis and representation play an important role in visual perception. As such, texture information is used
in several computer-vision, remote-sensing, medical-imaging and content-based image retrieval applications. In this research,
we focus on building new statistical methods based on finite mixture models for wavelet/contourlet coefficients representation.
Recently, we used the MoGG formalism for wavelet/contourlet coefficients modeling. MoGG gathers the advantages of using the Generalized Gaussian
Density (GGD) and mixture modeling to provide a powerful tool to fit multimodal data histograms with heavy-tailed and sharply peaked modes.
Compared to mixture of Gaussians (MoG), MoGG
achieves high precision data fitting using lesser numbers of components (i.e., model parsimony). These properties make
it an ideal tool to represent different shapes of wavelet/contourlet subband histograms. It provides also precise signatures for texture
discrimination and retrieval.
wavelet modeling.
Papers :
- Wavelet Modeling Using Finite Mixtures of Generalized Gaussian Distributions: Application to Texture Discrimination and Retrieval. IEEE TIP, 21(4): 1452-1464, 2012.
- Wavelet-Based Texture Retrieval Using a Mixture of Generalized Gaussian Distributions. ICPR, 3143-3146, 2010.
- (with N. Baaziz and M. Mejri). Texture Modeling Using Contourlets and Finite Mixtures of Generalized Gaussian Distributions and Applications. IEEE TM, 16(3): 772-784, 2014.
- N. Baaziz. Contourlet-Based Texture Retrieval Using a Mixture of Generalized Gaussian Distributions. Int'l Conf. on Computer Analysis of Images and Patterns (CAIP), LNCS 6855, 446--454, 2011.
|
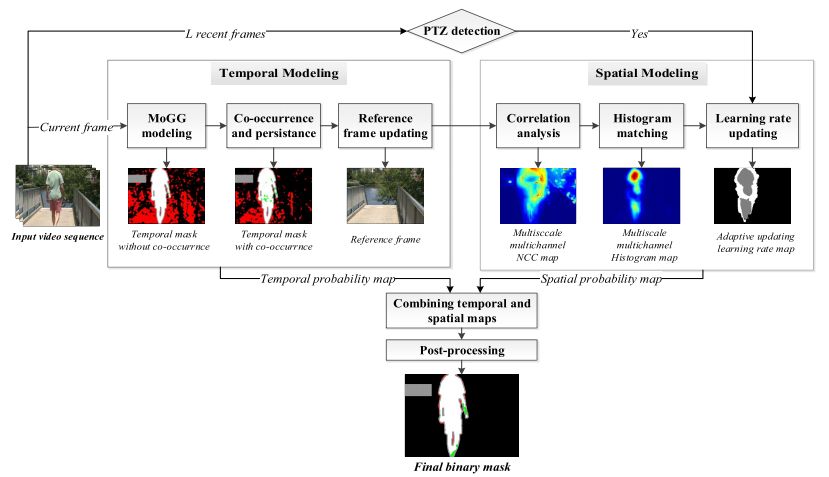
a) Video foreground segmentation combining temporal and spatial information
|
We present a new statistical approach combining temporal and spatial information for robust online background subtraction (BS) in videos.
Temporal information is modeled by coupling finite mixtures of generalized Gaussian distributions with foreground/background co-occurrence analysis.
Spatial information is modeled by combining multiscale inter-frame correlation analysis and histogram matching. We propose an online algorithm that
efficiently fuses both information to cope with several BS challenges, such as cast shadows, illumination changes, and various complex background dynamics.
In addition, global video information is used through a displacement measuring technique to deal with pan-tilt-zoom camera effects. Experiments with comparison
with recent state-of-the-art methods have been conducted on standard data sets. Obtained results have shown that our approach surpasses several state-of-the-art
methods on the aforementioned challenges while maintaining comparable computational time.
Papers :
- (with A. Boulmerka). Foreground Segmentation in Videos Combining General Gaussian Mixture Modeling and Spatial Information. IEEE TCSVT, 28(6): 1330-1345, 2018.
- (with D. Ziou and N. Bouguila). Finite general Gaussian mixture modeling and application to image and video foreground segmentation. JEI, 17(1): 013005 (2008).
|
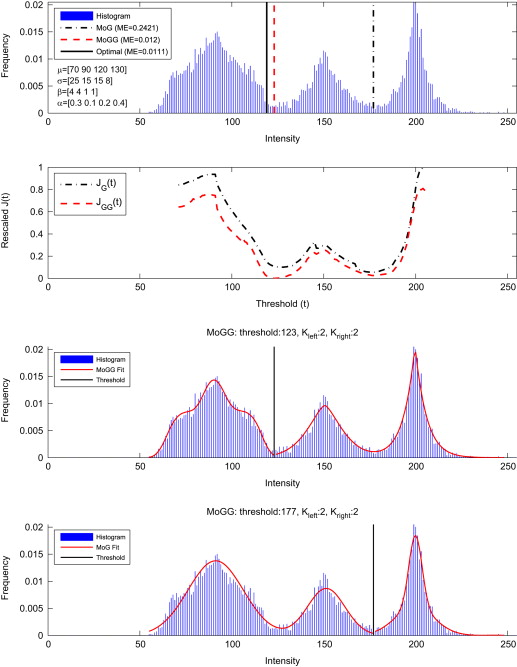
b) Multimodal histogram thresholding based MoGG modeling
|
We present a new approach to multi-class thresholding-based segmentation. It considerably improves existing thresholding methods
by efficiently modeling non-Gaussian and multi-modal class-conditional distributions using mixtures of generalized Gaussian distributions (MoGG).
The proposed approach seamlessly: (1) extends the standard Otsu's method to arbitrary numbers of thresholds and (2) extends the Kittler and Illingworth
minimum error thresholding to non-Gaussian and multi-modal class-conditional data. MoGGs enable efficient representation of heavy-tailed data and multi-modal
histograms with flat or sharply shaped peaks. Experiments on synthetic data and real-world image segmentation show the performance of the proposed approach
with comparison to recent state-of-the-art techniques.
Papers :
- (with A. Boulmerka). A generalized multiclass histogram thresholding approach based on mixture modelling. Pattern Recognition, 47(3): 1330-1348, 2014.
- (with A. Boulmerka). Thresholding-based segmentation revisited using mixtures of generalized Gaussian distributions. IEEE ICPR, 2894-2897, 2012.
|
c) Feature selection in MoGGs for segmentation

|
In this letter, we propose a clustering model that efficiently mitigates image and video under/over-segmentation by
combining generalized Gaussian mixture modeling and feature selection. The model has flexibility to accurately represent
heavy-tailed image/video histograms, while automatically discarding uninformative features, leading to better discrimination
and localization of regions in high-dimensional spaces. Experimental results on a database of real-world images and videos
showed us the effectiveness of the proposed approach.
Papers :
- (with D.Ziou, N. Bouguila and S. Boutemedjet. Image and Video Segmentation by Combining Unsupervised Generalized Gaussian Mixture Modeling and Feature Selection. IEEE TCSVT, 20(10): 1373-1377 (2010)
|
d) Robust image/video foreground segmentation using MoGGs
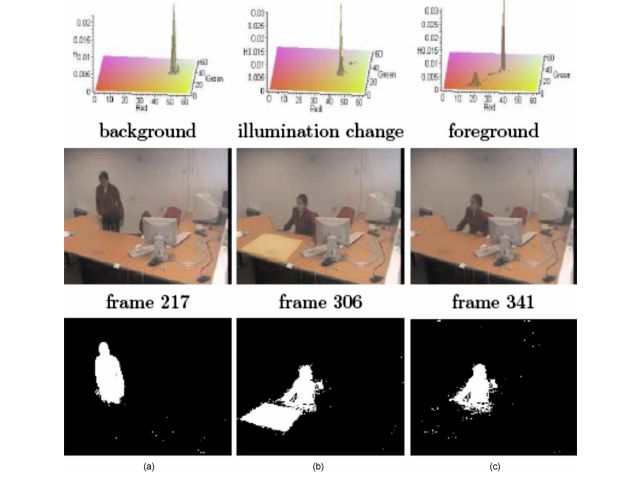
|
We propose a new finite mixture model based on the formalism of general Gaussian distribution (GGD). Because it has the flexibility
to adapt to the shape of the data better than the Gaussian, the GGD is less prone to overfitting the number of mixture classes when dealing with noisy data.
In the first part of this work, we propose a derivation of the maximum likelihood estimation for the parameters of the new mixture model, and elaborate an information-theoretic
approach for the selection of the number of classes. In the second part, we validate the proposed model by comparing it to the Gaussian mixture in applications related to image and
video foreground segmentation.
Papers :
- (with A. Boulmerka and S. Ait Aoudia). A generalized multiclass histogram thresholding approach based on mixture modelling. PR, 47(3): 1330-1348 (2014)
- (with N. Bouguila, D. Ziou). Finite general Gaussian mixture modeling and application to image and video foreground segmentation. JEI, 17(1): 013005 (2008).
|
a) Adaptive region Information for color-texture image segmentation

|
We propose an automatic segmentation of colortexture images with arbitrary numbers of regions. The approach combines
region and boundary information and uses active contours to build a partition of the image. The segmentation algorithm
is initialized automatically by using homogeneous region seeds on the image domain. The partition of the image is formed
by evolving the region contours and adaptively updating the region information formulated using a mixture of pdfs. We show
the performance of the proposed method on examples of colortexture image segmentation, with comparison to two state-of-the-art methods.
Papers :
- (with D. Ziou). Object-of-Interest segmentation and Tracking by Using Feature Selection and Active Contours. IEEE CVPR, 1-8, 2007.
- (with D. Ziou). Globally adaptive region information for automatic color-texture image segmentation. PRL, 28(15): 1946-1956, 2007.
- (with D. Ziou). Using Feature Selection For Object Segmentation and Tracking. IEEE CRV, 191-200, 2007.
- (with D. Ziou). An automatic segmentation of color images by using a combination of mixture modelling and adaptive region information: a level set approach. ICIP, (1): 305-308, 2005.
|
b) Color-texture image segmentation combining region and boundary information
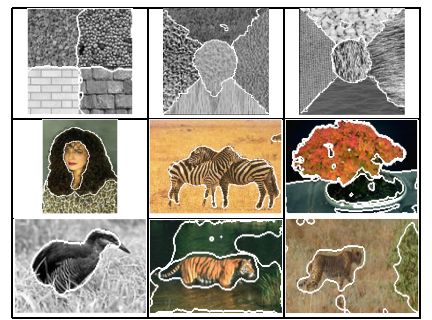
|
we propose a fully automatic segmentation method for colour/texture images. By fully automatic, we mean that the steps
of region initialization and calculation of the number of regions are performed automatically by the method. The region information is formulated
using a mixture of pdfs for the combination of colour and texture features. The segmentation is obtained by minimizing an energy functional
combining boundary and region information, which evolves the initial region contours towards the real region boundaries and adapts the mixture
parameters to the region data. The method is implemented using the level sets that permit automatic handling of topology changes and stable numerical
schemes. We validate the approach using examples of synthetic and natural colourtexture image segmentation.
Papers :
- (with D. Ziou). Automatic colour-texture image segmentation using active contours. Int. J. Comput. Math, 84(9): 1325-1338, 2007.
- (with D. Ziou). Automatic Color-Texture Image Segmentation by Using Active Contours. IWICPAS, 495-504, 2006.
|
c) Object tracking in videos using level sets and adaptive region informationn

|
we propose a novel object tracking algorithm for video sequences, based on active contours. The tracking
is based on matching the object appearance model between successive frames of the sequence using active contours.
We formulate the tracking as a minimization of an objective function incorporating region, boundary and shape information. Further,
in order to handle variation in object appearance due to self-shadowing, changing illumination conditions and camera geometry, we propose
an adaptive mixture model for the object representation. The implementation of the method is based on the level set method. We validate our
approach on tracking examples using real video sequences, with comparison to two recent state-of-the-art methods.
Papers :
- (with D. Ziou). Mohand Saïd Allili, Djemel Ziou: Active contours for video object tracking using region, boundary and shape information. SIVP, 1(2): 101-117 (2007)
- (with D. Ziou). Object tracking in videos using adaptive mixture models and active contours. Neurocomputing 71(10-12): 2001-2011 (2008)
- Effective object tracking by matching object and background models using active contours. IEEE ICIP 2009: 873-876
|